





Bagi yang kerap mengandalkan ChatGPT dalam mengerjakan berbagai tugas sehari-hari, harus diakui bahwa jawaban yang diberikannya memang memuaskan. Namun kita juga tahu, jawaban tersebut belum tentu benar dan harus dicek ulang kebenarannya.
Kabar terbaru, para peneliti OpenAI telah meluncurkan CriticGPT. Model AI baru berbasis GPT-4 yang dirancang untuk mengidentifikasi kesalahan dalam kode yang dihasilkan oleh ChatGPT.
CriticGPT bertujuan untuk meningkatkan proses membuat sistem AI bertindak sesuai keinginan manusia (disebut “alignment”) melalui Reinforcement Learning from Human Feedback (RLHF), yang membantu peninjau manusia membuat keluaran model bahasa besar (LLM) lebih akurat.
Dalam makalah penelitian baru berjudul “LLM Critics Help Catch LLM Bugs,” OpenAI menciptakan CriticGPT sebagai asisten AI bagi pelatih manusia yang meninjau kode pemrograman yang dihasilkan oleh asisten AI ChatGPT.
CriticGPT akan menganalisis kode dan menunjukkan potensi kesalahan, membuatnya lebih mudah bagi manusia untuk menemukan kesalahan yang mungkin terlewatkan. Para peneliti melatih CriticGPT dengan dataset sampel kode yang memiliki bug yang disisipkan secara sengaja, mengajarinya untuk mengenali dan menandai berbagai kesalahan coding.
Pengembangan CriticGPT melibatkan pelatihan model dengan sejumlah besar input yang berisi kesalahan yang disisipkan secara sengaja. Pelatih manusia diminta untuk memodifikasi kode yang ditulis oleh ChatGPT, memperkenalkan kesalahan dan kemudian memberikan umpan balik contoh seolah-olah mereka telah menemukan bug tersebut. Proses ini memungkinkan model belajar cara mengidentifikasi dan mengkritik berbagai jenis kesalahan coding.
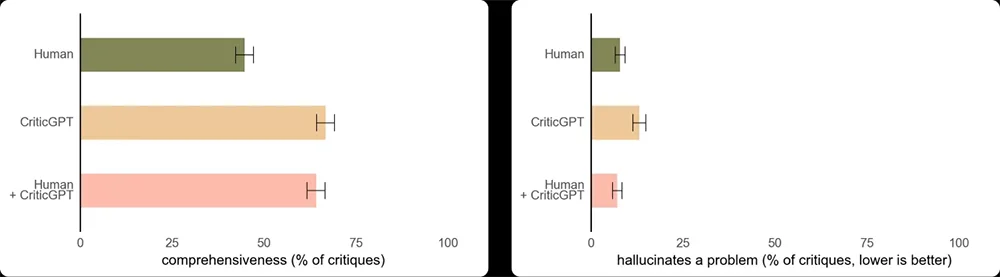
Dalam eksperimen, CriticGPT menunjukkan kemampuannya menangkap baik bug yang disisipkan maupun kesalahan alami dalam output ChatGPT. Kritik model baru ini lebih disukai oleh pelatih dibandingkan dengan kritik yang dihasilkan oleh ChatGPT sendiri dalam 63 persen kasus yang melibatkan bug alami. Preferensi ini sebagian karena CriticGPT menghasilkan lebih sedikit “nitpicks” yang tidak membantu dan lebih sedikit menghasilkan positif palsu atau masalah yang dihalusinasi.
Meskipun hasilnya menjanjikan, seperti semua model AI dari OpenAI, CriticGPT memiliki keterbatasan. Model ini dilatih pada jawaban ChatGPT yang relatif pendek, yang mungkin tidak sepenuhnya mempersiapkannya untuk mengevaluasi tugas yang lebih panjang dan kompleks yang mungkin dihadapi sistem AI di masa depan. Selain itu, meskipun CriticGPT mengurangi konfabulasi, model ini tidak menghilangkannya sepenuhnya, dan pelatih manusia masih dapat membuat kesalahan penandaan berdasarkan output yang salah ini.
Tim peneliti mengakui bahwa CriticGPT paling efektif dalam mengidentifikasi kesalahan yang dapat ditemukan di satu lokasi spesifik dalam kode. Namun, kesalahan dunia nyata dalam output AI sering kali tersebar di beberapa bagian jawaban, yang menjadi tantangan bagi iterasi model di masa depan. Para peneliti memperingatkan bahwa meskipun dengan alat seperti CriticGPT, tugas atau respons yang sangat kompleks mungkin tetap menantang bagi penilai manusia, bahkan mereka yang dibantu oleh AI.















